Deliver AI voice agents that perform with real users
Evalgent helps voice AI teams evaluate and ship production-ready agents faster and with confidence.
Refund Flow v2.1
ID: 2fccb77d... · Executed: Mar 28, 2026
Problems teams face without an evaluation layer
Voice agents work in demos but break with real users
Demos don't reflect real behavior. Without a structured evaluation layer, teams lack a way to validate agents across scenarios and human interaction patterns before deployment.
Teams can't tell if failures are edge cases or systemic
Without repeatable evaluation, teams can't distinguish one-off failures from underlying reliability issues.
There's no visibility into how much user behavior agents can tolerate
In the absence of behavioral limit testing, deployment decisions rely on intuition rather than defined failure boundaries.
Fixing one issue often breaks something else
Without a consistent re-evaluation framework, regressions go undetected across agent iterations.
How we solve them
Scenario-driven functional evaluation
We define success at the scenario level and test whether the agent actually completes the intended objective end-to-end.
Learn more about Scenario-driven functional evaluationRefund request
Objective: Complete the refund process end-to-end
Success criteria
Behavioral testing with human interaction profiles
We stress agents using real human behavior patterns instead of ideal users.
Learn more about Behavioral testing with human interaction profilesLimit testing to define failure boundaries
We push behavior and conditions until reliability drops below acceptable thresholds.
Learn more about Limit testing to define failure boundariesStatistical reliability measurement
Every test is run multiple times to measure consistency, not luck.
Learn more about Statistical reliability measurementEvidence-backed outcomes
Every success or failure is explainable and auditable.
Learn more about Evidence-backed outcomesHi, how can I help you today?
I need to cancel my subscription
Sure, let me look up your account. Can you provide your email?
I'd be happy to help you upgrade your plan!
How does it work?
Define
Lock real scenarios and success criteria.
Run
Run them under realistic human behavior.
Measure
See what works, what fails, and where limits lie.
Act
Get clear, actionable insights on what to fix, tune, or deploy.
Evaluation is infrastructure
Post-hoc analysis on production transcripts
A pre-deployment testing layer that surfaces failures before users do
Post-hoc analysis on production transcripts
A pre-deployment testing layer that surfaces failures before users do
LLM-as-judge scoring alone
A controlled execution framework with defined scenarios and behaviors
LLM-as-judge scoring alone
A controlled execution framework with defined scenarios and behaviors
Optional or "nice to have"
Foundational infrastructure for shipping reliable voice agents
Optional or "nice to have"
Foundational infrastructure for shipping reliable voice agents
A reporting or monitoring tool
A decision layer that determines production readiness
A reporting or monitoring tool
A decision layer that determines production readiness
From the blog
Practical guides on voice agent testing, evaluation, and production reliability.
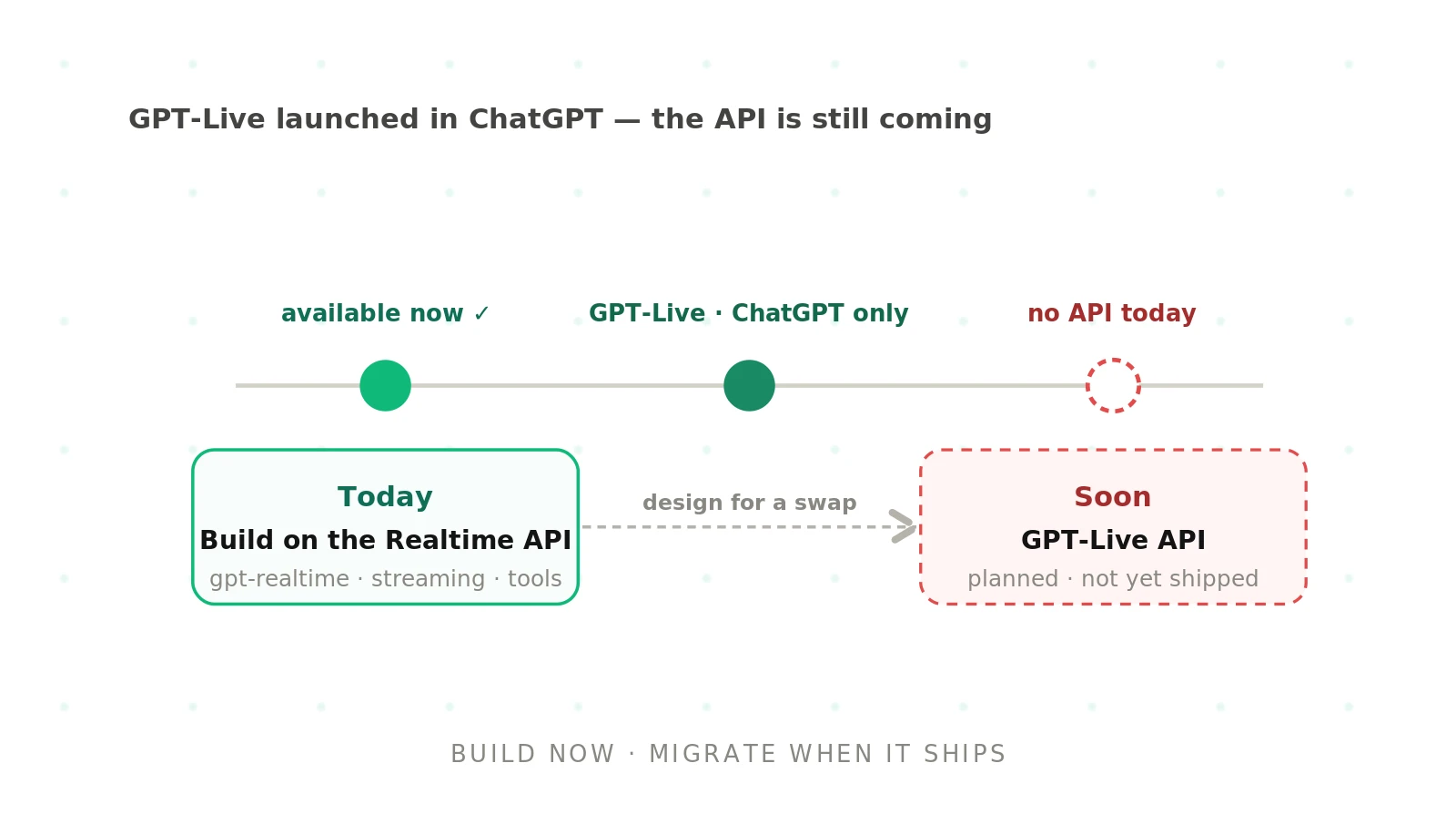
How to build voice agents with GPT-Live (and what to do until the API ships)
GPT-Live changes how you architect a voice agent, not just which model you call. Learn what full-duplex changes and what to build until the API ships.
Read more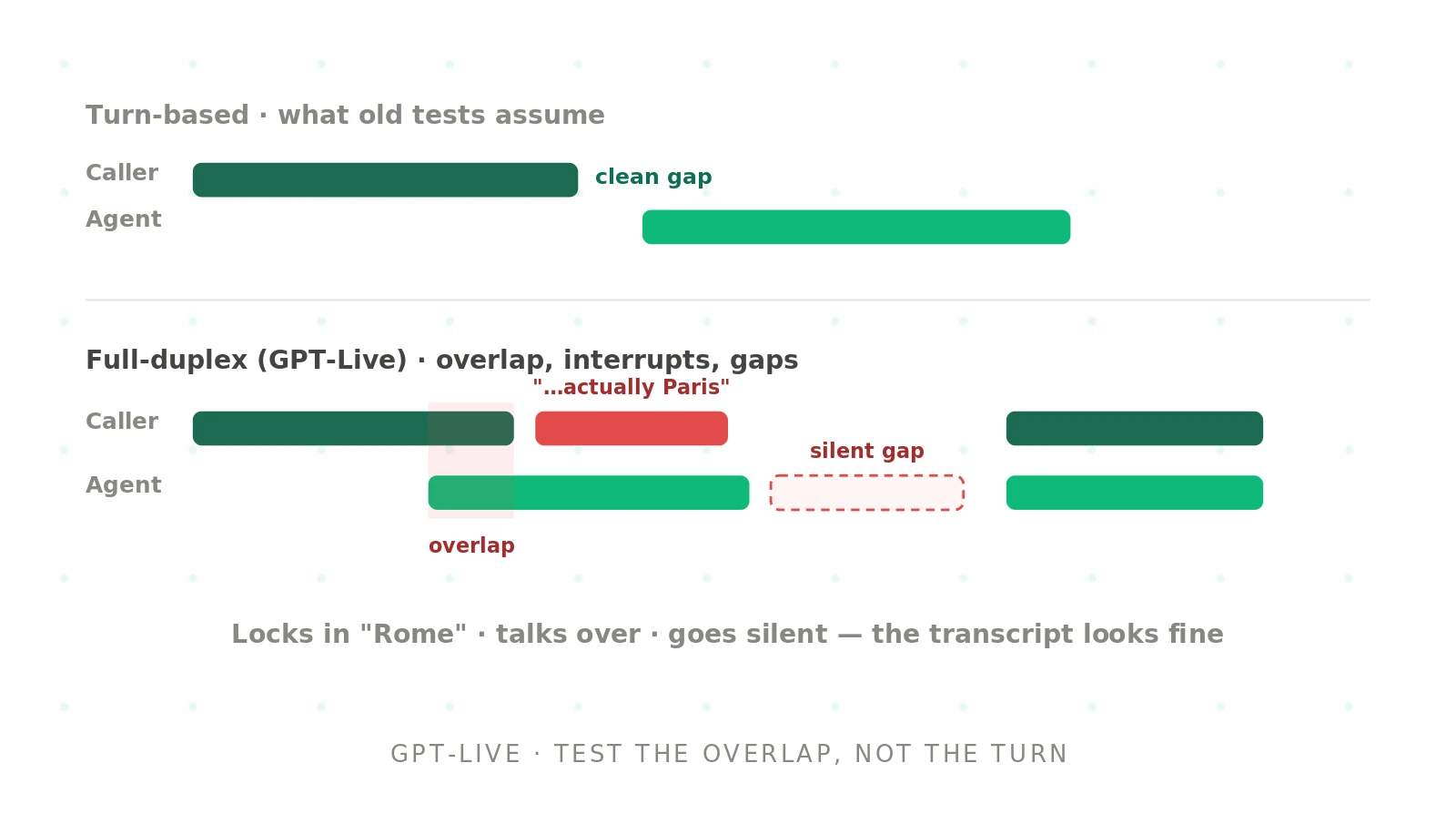
How to test GPT-Live voice agents: the new failure modes of full-duplex
GPT-Live is full-duplex, so it breaks the clean-turn assumption most tests rely on. Learn the new failure modes and how to test a GPT-Live voice agent.
Read more
Voice agent testing for food ordering: order accuracy, modifiers, and noise
Food ordering voice agents take orders over noisy lines full of modifications. Learn how to test one for order accuracy and noise robustness.
Read more