Test your voice agent
Voice agent regression testing: why LLM updates break production
You shipped a better model. The benchmarks were unambiguous: lower latency, higher accuracy on ambiguous queries, cleaner handling of edge cases. The A/B test in staging looked promising. Your team celebrated and pushed to production.
By the next morning, your customer success team was fielding tickets.
"The agent can't understand appointment requests."
"It keeps repeating itself when customers ask about refunds."
"The whole verification flow is broken."
Nothing in your ai testing predicted this. The new model was objectively better by every metric you measured. And yet, it broke conversations that had been working reliably for months.
Welcome to the voice agent regression problem — the pattern where improving one component of your voice AI pipeline introduces failures in other components in ways that standard evaluation and benchmark comparison completely miss.
This is not a rare edge case. It happens to nearly every team that upgrades a model in production without dedicated ai testing for behavioral regressions. And it happens because of five predictable, well-understood mechanisms that pre-deployment voice agent testing is specifically designed to catch. Understanding how to prevent voice agent regressions before they reach users — and how to build the agent testing infrastructure that catches them automatically — is what this article covers.
Why model updates cause regressions in voice agents
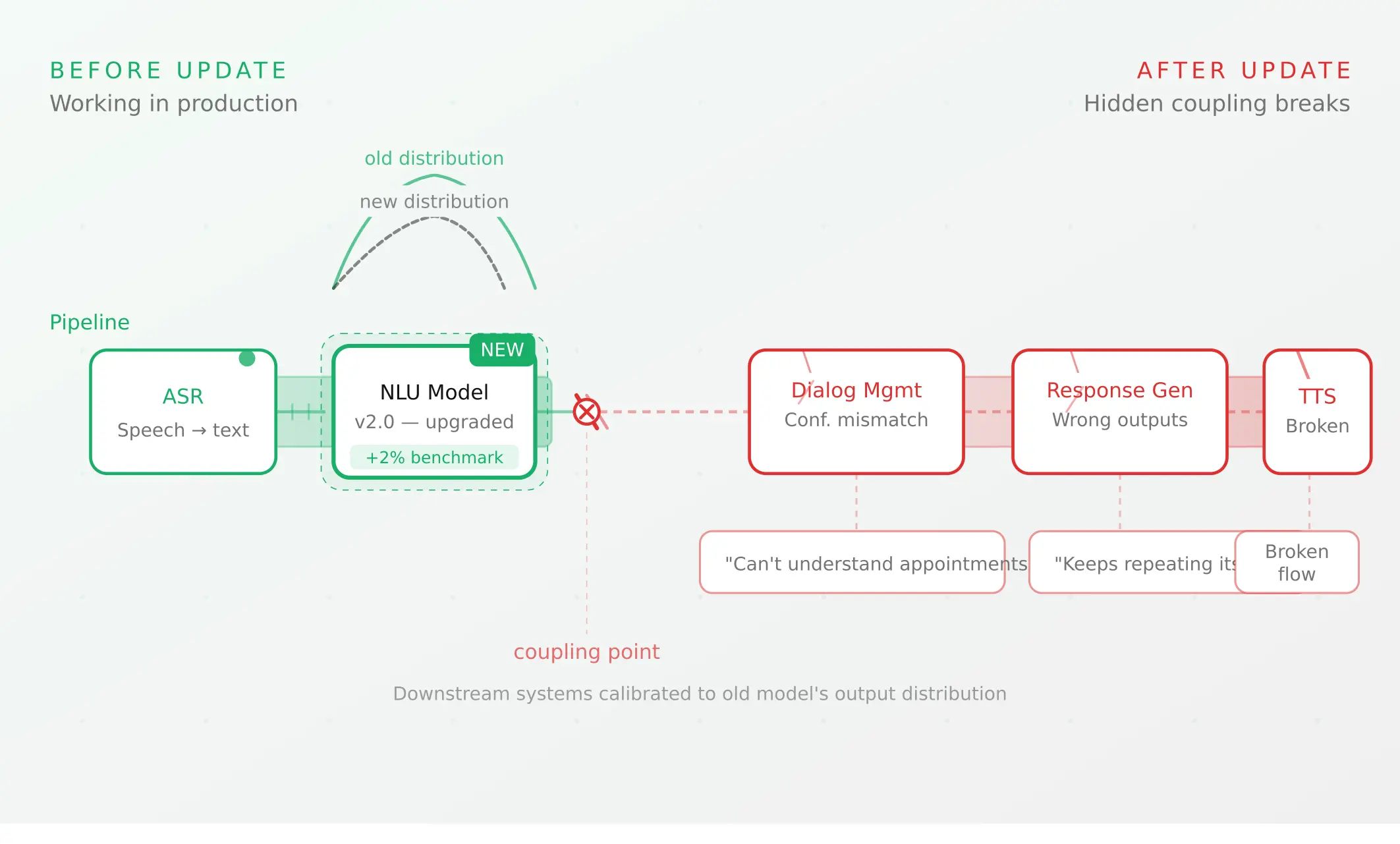
Model updates cause regressions because a voice AI pipeline is not a single system — it is a series of interconnected components, each calibrated to the output characteristics of the components upstream of it. When you update one component, you change its output distribution. Downstream components that were tuned for the previous distribution can fail in ways that neither the old nor the new component would produce in isolation.
This is the hidden coupling problem, and it is present at every interface in a voice agent stack. The gap between ai in testing environments and production ai behaviour is precisely where these coupling failures live — invisible in isolated component tests, visible only when the full pipeline runs under real conditions.
Consider a concrete example. Your dialogue management system has learned that when the NLU outputs intent: check_balance with a confidence score above 0.85, it proceeds directly to the balance lookup. Below 0.85, it asks a clarifying question. This calibration was correct for your previous model.
You upgrade your LLM. The new model is more accurate overall — but it outputs confidence scores more conservatively, clustering around 0.75–0.85 rather than the previous 0.80–0.95 range. Suddenly, conversations that previously flowed directly to the balance lookup now trigger a clarifying question. Users who asked "What's my balance?" are now being asked "Did you mean you want to check your account balance?" The intent recognition is actually more accurate — but the downstream system interprets the confidence scores using the old calibration, and the user experience degrades.
This is coupling in action. The problem is not the new model. The problem is that ai testing did not verify behavioural equivalence at the component interfaces before deployment.
The 5 mechanisms that turn model updates into production failures
1. Output distribution shifts
Every model produces outputs with a characteristic statistical distribution. Confidence scores, response lengths, token probabilities, latency patterns — all follow distributions that downstream systems implicitly learn to expect through calibration, thresholding, and timeout logic.
When you update a model, these distributions shift. Even when the new distributions are objectively better by standard metrics, systems calibrated to the old distributions can fail in unpredictable ways. The most common distribution shifts that cause production failures are:
- Confidence score recalibration. New models often produce systematically different confidence distributions — more conservative or more assertive — which breaks downstream decision thresholds tuned to the previous model
- Response length changes. If your TTS provider or timeout logic assumes responses below a certain length, a model that generates longer confirmations can trigger timeout errors or audio truncation
- Latency variance changes. A model that is faster on average but slower on edge cases can break turn-detection and barge-in logic tuned to the previous latency profile
Ai and testing for distribution shifts requires monitoring output characteristics at every component boundary — not just final task completion rates. This is why ai in testing environments often fails to surface these issues: isolated component tests do not expose the calibration mismatches that emerge in the full pipeline.
2. Prompt sensitivity changes
Prompt-based systems are acutely vulnerable to model updates. The relationship between a prompt and a model's response is model-specific — a prompt that produced reliable behaviour in one model version may behave differently in the next.
Common prompt sensitivity regressions include:
- Instructions followed reliably in the previous model being ignored or interpreted too literally by the new one
- Formatting instructions producing different output structure, breaking downstream parsing logic
- Edge case handling changing — a model that previously returned "intent": "unknown" for out-of-domain queries may now attempt to handle them, routing conversations incorrectly
- Tone and formality shifts that affect downstream sentiment detection or escalation logic
The implication for ai testing: Every prompt change — even a single word — requires regression ai testing across the full scenario suite, not just a visual review of the diff. This is the most underestimated trigger for voice agent regressions in production.
3. Latency profile changes
Voice agents are real-time systems. Users have calibrated expectations about conversational timing, and the components that manage turn-taking, barge-in detection, and interruption handling all depend on response latency being predictable within a known range.
Model updates routinely alter latency profiles:
- A model faster on average but with a higher P95 can cause 1 in 20 conversations to feel unnaturally sluggish — enough to affect user experience metrics without appearing as an obvious error
- Changes in token generation variance affect when TTS can begin streaming, altering perceived responsiveness
Hamming's analysis of 4M+ production voice agent calls shows median P50 response time of 1.5–1.7 seconds, with P95 calls waiting 3 seconds or more. A latency shift moving your P95 from 2.8 seconds to 3.5 seconds may not change your median — but represents significant degradation for your slowest calls.
Ai testing for latency regressions requires monitoring P90, P95, and P99 latency percentiles across the full scenario suite, not just average response time.
4. Error mode transitions
Every model has a characteristic signature of how it fails. Your voice agent pipeline has been built to handle the specific failure modes of your current components: fallback strategies for low-confidence responses, retry logic for specific error types, graceful degradation for timeout patterns.
When you update a model, the failure signature changes. The new model may fail less frequently — but when it does fail, it may fail in ways your pipeline was never designed to handle.
Common error mode transitions include:
- Confident errors replacing uncertain ones. The previous model returned low-confidence signals on out-of-domain queries, triggering clarification flows. The new model returns confident but incorrect responses, bypassing those flows entirely.
- New failure types with no handler. A model trained on different data may produce syntactically valid but semantically broken outputs that pass format validation but fail downstream logic.
- Retry logic incompatibility. If your retry logic was designed around the previous model's error taxonomy, the new model's different error types may not trigger the right recovery paths.
This category of regression is invisible to benchmark testing. A model that produces more correct answers overall can still introduce net-negative production outcomes if it fails differently in the scenarios your pipeline depended on handling through fallback paths.
5. Training data distribution mismatch
Models are trained on specific data distributions. When you update to a newer model trained on different data, you change what the model considers normal conversational input. For voice agents, this is especially consequential because:
- ASR output patterns. Voice agent LLMs receive transcribed speech, not clean text. The transcription errors, fillers, and disfluencies in ASR output have their own distribution. A model trained heavily on formal text may misinterpret the messy patterns that real ASR systems produce.
- Domain-specific terminology. A general-purpose LLM update may have been trained on a broader corpus with less domain-specific content. Terminology that was handled reliably can become unreliable after the update.
- Conversational register. Models handle informal, spoken register with different facility depending on their training data. A model that performs well on polished text may misinterpret common spoken idioms.
Why standard ai and testing misses these regressions
Benchmark blindness
Standard benchmarks measure average performance across a curated test set. A model scoring 2% higher on a benchmark may score 30% lower on the specific subset of production traffic that relies on failure handling that has changed. Regressions hide in the unmeasured spaces: the long tail of rare inputs, component interactions, and behaviours that only emerge under production load. No amount of benchmark ai testing surfaces these — only behavioural ai testing against a real production scenario distribution does.
Integration test limitations
End-to-end tests help but have structural limitations:
- Test sets reflect the past. A test set built when the previous model was deployed tests the old model's success cases — not the new model's novel failure modes.
- Deterministic timing. A regression in latency variance is invisible in low-variance test conditions.
- Coverage gaps. Component integration tests check happy paths. They do not capture how component interactions fail under the new model's output distribution.
The confidence paradox in ai evaluation
The more a new model improves on the cases you measure, the more confident you become in deploying it — but the cases you measure are precisely the ones where regressions are least likely. This is why agent evaluation for model updates must explicitly test for behavioural equivalence. In production ai systems, behavioural equivalence — not benchmark superiority — determines user experience, and it is only discoverable through systematic ai testing against a defined baseline.
Voice agent regression testing: a 5-step checklist
The following five-step framework applies to every model update — LLM version changes, prompt edits, STT provider switches, TTS model changes, and integration updates. Any change to a component in the pipeline is a regression risk and requires ai testing against the baseline.
1. Establish a behavioural baseline before the update. Before any change, run your full scenario suite and record detailed output metrics at every component boundary: confidence score distributions, response lengths, latency percentiles (P50, P90, P95, P99), error types and rates, and task completion rates by scenario category. This baseline is what you are protecting.
2. Define equivalence thresholds. Determine what constitutes an acceptable deviation from the baseline for each metric. Typical thresholds: task completion rate must not drop more than 3%, P95 latency must not increase more than 20%, escalation rate must not increase more than 5%, WER must not increase more than 2 percentage points (calibrate your ASR baseline against Deepgram's WER benchmarks for your specific provider and acoustic conditions). These numbers should reflect your specific user experience requirements.
3. Run regression testing against the baseline. Execute the full scenario suite against the updated component. Compare every output metric against the baseline. A regression is any deviation that exceeds the equivalence thresholds — regardless of whether the new model scores higher on external benchmarks. Use automated evaluation to make this feasible at the required frequency.
4. Test specifically for error mode transitions. Add adversarial test scenarios designed to probe the new model's failure boundaries: out-of-domain queries, low-confidence inputs, edge cases from the tails of your input distribution. These scenarios should be designed to expose failure modes you have not yet seen, not just to verify previously working cases.
5. Gate deployment on passing every threshold. Block the deployment if any metric falls below the equivalence threshold. This is the critical discipline that separates teams with reliable voice agents from teams that discover regressions in production. A model that benchmarks higher but fails regression testing is not ready to deploy, regardless of how promising the benchmark looks.
Voice agent ci/cd testing: integrating regression detection into your pipeline
Voice agent regression testing is only as effective as its frequency. A regression suite run quarterly catches far fewer problems than one that runs on every deployment. The goal is to make ai testing automatic, fast, and integrated into your development workflow.
Trigger on every change, not just major releases. Prompt edits, model version bumps, STT provider changes, and integration updates are all deployment events that should trigger the regression suite. The Hamming AI team documented a production incident caused by changing a single word in a greeting prompt — a change that seemed cosmetic but altered intent classification for a significant portion of conversation paths.
Maintain parallel environments. Run the old and new versions simultaneously on the same test traffic. Compare outputs at the scenario level, not just in aggregate. Divergences between old and new — even on cases both handle correctly — can indicate distribution shifts that will manifest as integration failures at scale.
Convert every production failure into a permanent test case. When a real user has a bad experience after a model update, add that call to the regression suite. Over time, your test library evolves from imagined scenarios into a corpus built from actual production failures — the mechanism by which your ai testing practice becomes more valuable with every cycle. Our guide to synthetic callers for voice agent testing describes the same golden call set approach in detail.
Monitor component-level metrics post-deployment. Track output distributions at every component boundary after going live. Set automated alerts when any metric deviates more than 10% from the post-deployment baseline.
If ai testing catches a regression but you cannot isolate the root cause, the stress-testing framework provides techniques for identifying which component is responsible. If you are evaluating whether your current evaluation approach is comprehensive enough, why transcript analysis falls short covers the specific blind spots that LLM scoring cannot detect.
The platforms teams typically use include Hamming AI (strong for CI/CD integration and concurrent synthetic call testing), Coval (autonomous vehicle-inspired regression methodology), and Evalgent's evaluation platform for scenario-based behavioural regression testing.
How to test after an llm update: a decision matrix
When an llm update breaks voice agent performance, the failure usually falls into one of the five categories above. But not every model update carries the same regression risk. Use this matrix to determine how to test after llm update events and apply the right depth of ai testing for each change type before deployment.
| Change type | Risk level | Minimum regression scope | Recommended testing depth |
|---|---|---|---|
| Minor LLM version bump (e.g. GPT-4o-mini → GPT-4o-mini-2) | Medium | Golden call set (100+ scenarios) | Full scenario suite + distribution analysis |
| Major LLM change (e.g. GPT-4o → Claude 3.5 Sonnet) | High | Full scenario suite | Full suite + adversarial edge cases + latency profiling |
| System prompt edit (any) | Medium–High | Affected flows + regression suite | Full scenario suite — prompt changes are underestimated risks |
| STT provider change (e.g. Deepgram → AssemblyAI) | High | Full scenario suite + acoustic profiles | Full suite across all accent and noise profiles |
| TTS provider change (e.g. ElevenLabs → Cartesia Sonic) | Medium | Latency and interruption scenarios | Latency profiling + barge-in detection testing |
| Integration update (CRM, booking API) | Medium | Affected task flows | Affected flows + downstream verification |
| Infrastructure change (telephony provider, codec) | High | Full acoustic profile suite | Full suite across telephony conditions |
Teams using Vapi or Retell can trigger regression suites through their CI/CD pipeline using webhooks. For teams building on LiveKit or Pipecat, the same scenario runner can be deployed against any endpoint that accepts calls — the testing infrastructure is independent of the underlying platform.
The organisational dimension of regression testing
Teams are incentivised to ship improvements. A benchmark showing "2% better accuracy" is a tangible win. A regression test run that confirms "nothing broke" is invisible — the absence of an incident does not get presented in sprint reviews.
Building a culture of ai and testing for regressions requires making the absence of breakage visible. Track regression test results as a first-class metric. When agent testing blocks a deployment, that is a prevented production incident — more valuable than the feature that was blocked.
Knowing how to prevent voice agent regressions at the organisational level means treating ai testing as a product discipline. Teams that sustain this culture ship faster long-term, because they accumulate less production incident debt.
Summary
Every model update is a regression risk, regardless of how much better it benchmarks. The five mechanisms — output distribution shifts, prompt sensitivity changes, latency profile changes, error mode transitions, and training data mismatch — are predictable, testable, and preventable. They are not caught by benchmark comparison because benchmarks measure average performance on idealised test sets. They are caught by voice agent regression testing that compares behavioural equivalence across the full production scenario distribution.
The discipline is straightforward: establish a behavioural baseline before every change, define equivalence thresholds, run systematic ai testing against those thresholds before deployment, and gate on passing every threshold. Teams that build this ai testing practice consistently discover regressions in their evaluation environment rather than in their users' experience.
Frequently asked questions
What is voice agent regression testing?
Voice agent regression testing runs a defined scenario suite against an updated pipeline component and verifies that output metrics — task completion rate, latency percentiles, WER, error rates — remain within defined equivalence thresholds versus the pre-update baseline. The question is not whether the new model benchmarks higher, but whether it maintains the behaviours the rest of the pipeline depends on.
Why does updating an LLM break a voice agent that was working?
An LLM update shifts the output distribution of the language model — confidence scores, response lengths, latency profiles, error modes all change. Downstream components were calibrated to the previous distribution. When the distribution changes, those calibrations become misaligned, producing failures in flows that previously worked. The new model may benchmark higher and still cause net-negative production outcomes.
How do I test my voice agent after an LLM update?
Run your full behavioural scenario suite before deployment and compare every metric against the pre-update baseline. Key metrics: task completion rate (flag if it drops more than 3%), P95 latency (flag if it increases more than 20%), escalation rate (flag if it rises more than 5%), WER across accent and noise profiles. Block deployment if any metric falls outside your defined equivalence thresholds.
What is voice agent ci/cd testing?
Voice agent CI/CD testing integrates the regression scenario suite directly into the deployment pipeline, triggering automatically on every code change, prompt edit, or model update. The pipeline runs the golden call set, compares metrics against the baseline, and blocks deployment if any regression threshold is exceeded. This makes regression testing a continuous process rather than a periodic manual exercise.
How often should I run regression tests on a voice agent?
On every deployment event — including minor prompt edits, model version bumps, STT or TTS provider changes, and integration updates. The Hamming AI team documented a production regression caused by a single-word prompt change. Frequency matters because the cost of catching a regression in testing is orders of magnitude lower than the cost of discovering it in production.
What metrics should I track to detect voice agent regressions?
Track output distributions at every component boundary: confidence score distribution from the LLM, task completion rate by scenario category, P50/P90/P95/P99 latency, escalation rate, WER per acoustic and accent profile, and error type distribution. Monitoring averages alone is insufficient — regressions often manifest in the tails of distributions while leaving averages unchanged.
What is behavioral testing for voice agents?
Voice agent behavioral testing after model update verifies that the agent's end-to-end conversation patterns remain functionally equivalent to the pre-update baseline — not just that individual component metrics improved. It tests full conversation flows, including non-linear paths, correction handling, and edge cases, rather than isolated utterances. Behavioral equivalence, not benchmark superiority, is the deployment criterion.
How is regression testing different from benchmark testing for AI models?
Benchmark testing measures average performance on a curated set to determine if the new model outperforms the old one. Regression testing verifies behavioural equivalence across the full production scenario distribution, including component integration points. A model can benchmark higher and still fail regression testing if it changes behaviours downstream components depend on.
Related Articles
Why AI voice agents fail in production (and how to prevent it)
AI voice agents that ace demos still break in production. Learn the 5 root causes, how to test for each, and what production readiness actually means.
Read more
Voice agent stack: the complete guide
The complete voice agent stack: STT, LLM, TTS, orchestration, and telephony. Latency budget, cost per layer, build vs buy, and what to test before production.
Read more